Results API Reference
dt.scheduler.BatchRunResults
The BatchRunResults class is used to retrieve the results of runs of a specified Batch Job.
Usage:
To get the output of a given batch run, this class needs to be instantiated with a given Batch Job name.
Then, functions for accessing runs information and task outputs can be called on that instance.
The result will be loaded in a lazy way, i.e. only when a specific run is requested, then the result will be loaded from the database.
Examples:
The following would print the total number of runs of 'My Batch Job' and the reports of its runs –
from dt.scheduler import BatchRunResults
import pandas as pd
batch_runs = BatchRunResults('My Batch Job')
print(batch_runs.count)
runs = batch_runs.get_runs()
print(pd.DataFrame.from_dict(runs))
Parameters:
batch_name(str): The name of a Batch Job to retrieve results for.job_name(str), optional: Name of the job frombatch_name, for which to retrieve run data.
Methods:
count– Returns the total number of runs for the Batch Job.get_runs()– Returns the list of runs for the Batch Job.get_run()(run_id: int) – Returns the run with the given id.get_run_graph()(run_id: int) – Returns the dependencies between tasks that form a Directed Acyclic Graph.get_task_result()(run_id: int) – Returns the output of a task given the task run id
BatchRunResults interactive jupyter widget:
Requirements: ipywidgets >= 8.x, networkx, ipycytoscape, matplotlib, numpy
To start the widget, run the following code in JupyterLab:
from dt.scheduler import BatchRunResults
BatchRunResults('My Batch Job') # or display(BatchRunResults('My Batch Job'))
The UI allows you to view runs, see their status and scheduled time, filter by rundate or by a range of date and time. Inspect each run by clicking "Preview" button.
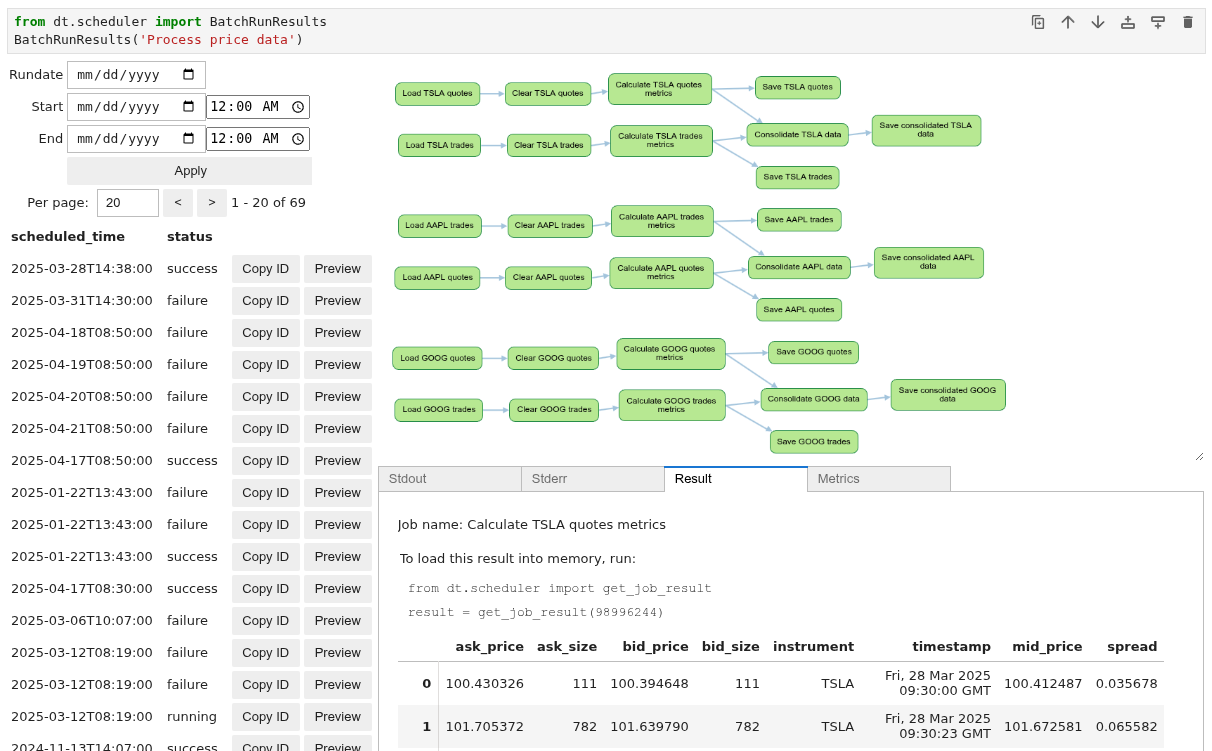 If only the batch name was specified, you will see a graph of your jobs, where you can click each node to preview stdout and stderr logs, metrics and the result. If the job name was specified as well, "Preview" button leads directly to strdout, stderr, metrics and results.
If only the batch name was specified, you will see a graph of your jobs, where you can click each node to preview stdout and stderr logs, metrics and the result. If the job name was specified as well, "Preview" button leads directly to strdout, stderr, metrics and results.
dt.scheduler.BatchRunResults.count
The total number of runs for the batch.
The name of the batch is determined during BatchRunResults object creation.
Example usage:
from dt.scheduler import BatchRunResults
results = BatchRunResults("My Batch")
print(results.count)
This script will print how many times the "My Batch" batch job was run.
dt.scheduler.BatchRunResults.get_runs()
Function for getting general information about batch runs or runs of specific jobs from a batch.
- If
job_namewas specified (duringBatchRunResultsobject creation or later), then the function will return information about runs of that job from the batch specified bybatch_name. - If
job_namewas not specified, the function will return information about all runs of the batch without job-specific data.
The result of this function is cached and the cache is invalidated every 5 minutes. To disable caching, set the disable_caching property to True. Also, changing batch_name or job_name, or calling get_runs() with different parameters will also invalidate cache and force the data to be loaded from the db.
Parameters:
rundate(str, date, or datetime), optional: rundate of the batch.
If specified, will return every run of the batch on that date. Cannot be used withrange_startandrange_end.range_start,range_end(str, date, or datetime), optional: Start and end of the time range for which to get runs. It's enough to specify one of them.- If specified, returns every run of the batch after (
range_start) and/or before (range_end). - Can be combined with each other, but not with
rundate. - If only date is provided, time defaults to 00:00:00.
- Accepted formats:
YYYY-MM-DDconverts toYYYY-MM-DD 00:00:00
YYYY-MM-DD HHconverts toYYYY-MM-DD HH:00:00
YYYY-MM-DD HH:MMconverts toYYYY-MM-DD HH:MM:00
YYYY-MM-DD HH:MM:SS
- If specified, returns every run of the batch after (
Returns:
- (List[dict]): The list of runs for the batch. Each run is represented by a dictionary with the following keys:
name(str),tag(str),scheduled_time(str),started_at(str),finished_at(str),
rundate(str),status(str),run_as(str),owner(str),group(str),permissions(str),
id(int),schedule_run_type(str).
Example usage:
from dt.scheduler import BatchRunResults
results = BatchRunResults("My Batch")
runs = results.get_runs()
print(pd.DataFrame.from_dict(runs))
This script will print the information about every run attempt of a batch named "My Batch".
dt.scheduler.BatchRunResults.get_run()
Function for retrieving information about all tasks run within the batch execution. This does not include dependencies between tasks or any of the task outputs.
Parameters:
run_id(int): id of the batch run. Can be found using theget_runs()function.
Returns:
- (List[dict]): The list of all tasks in the batch run. Each task run is represented by a dictionary with the following keys:
id(int),name(str),description(str),start(str),end(str),stdout(str),
stderr(str),configuration_json(dict),image(str),status(str),vm_id(str).
Note:
idof every task will be different in every batch run. Soidof a task from one batch run cannot be used to access a similar task from another run of the same batch.
Example usage:
from dt.scheduler import BatchRunResults
import pandas as pd
results = BatchRunResults("My Batch")
runs = results.get_runs()
# here you may inspect the data to get id of the run you want:
print(pd.DataFrame(runs))
# or get the latest one, which will be at the end of the list
run_id = runs[-1]['id']
task_runs = results.get_run(run_id)
print(pd.DataFrame.from_dict(task_runs))
Usually the get_runs() function call will be necessary to determine the id of the batch run, which then can be used to get the list of tasks in that run.
dt.scheduler.BatchRunResults.get_run_graph()
Function for getting the information task dependencies, including their names and statuses. This does not include task outputs.
Note: The only data provided here that is not present in the output of
get_run()function is dependency between tasks.
Parameters:
run_id(int): id of the batch run. Can be found using theget_runs()function
Returns:
- (dict): Dictionary with two keys:
statuses(list[dict]): A list of dictionaries storing information about each task with the following keys:
id(int),name(str),status(str),start_time(str),finish_time(str).dependencies(list[dict]): A list of dictionaries, each representing dependency between two tasks. In terms of DAG, this is a list of all its edges. Each dictionary has two keys:from(str),to(str) with task names as values.
dt.scheduler.get_job_result()
Function for retrieving the result of a job run given its id.
Parameters:
run_id(int): id of the job run. Can be found using theBatchRunResults.get_runs()function ifjob_namewas specified orBatchRunResults.get_run()if onlybatch_nameis specified.
Returns:
- (tuple): Tuple with two values:
- (str): The name of the task
- (any): The value returned by the entrypoint function of that task
Example usage:
from dt.scheduler import BatchRunResults, get_job_result
import pandas as pd
results = BatchRunResults("My Batch", "My Job")
runs = results.get_runs()
task_name, task_output = get_job_result(runs[-1]['id'])
Note: If the task execution failed, its output won't be stored in blob storage. Calling
get_task_result()on such job runs will raiseValueError.
dt.scheduler.get_job_metrics()
Function for retrieving CPU and memory metrics of a job run given its id.
Parameters:
run_id(int): id of the job run. Can be found using theBatchRunResults.get_runs()function ifjob_namewas specified orBatchRunResults.get_run()if onlybatch_nameis specified.
Returns:
- (dict): Dictionary containing CPU and Memory metrics with the following keys:
cpu_metrics_percentage: Array of float values. Can be more than 100.memory_metrics_absolute: Array of float values in MB.timestamps: Array of timestamps which correspond to cpu and memory datapoints. Same size ascpu_metrics_percentageandmemory_metrics_absolutearray.total_allocated_cpu: (int) CPU resources in MHz, allocated to the job.total_allocated_memory: (int) Memory in MB, allocated to the job.
dt.scheduler.get_job_logs()
Function for retrieving stdout and stderr metrics of a job run given its id.
Parameters:
run_id(int): id of the job run. Can be found using theBatchRunResults.get_runs()function ifjob_namewas specified orBatchRunResults.get_run()if onlybatch_nameis specified.
Returns:
- (dict): Dictionary containing
stdoutandstderrkeys storing contents ofstdoutandstderrlogs respectively.
dt.scheduler.get_batches()
The get_batches function is used to retrieve the list of all scheduled Batch Jobs, their schedules and dependencies. The same information is available on the "Batch Jobs" tab of the Job Scheduler.
Returns:
- (List[dict]): The list of dictionaries containing the information about scheduled Batch Jobs.
Updated 2 months ago